Event-Driven Architecture: Patterns, Cross-Service Communication, and Smarter Integration
/TABLE OF CONTENTS
/ARTICLE
/ARTICLE
[1]TLDR
- Event-driven architecture decouples services by having them publish and consume events through a broker rather than calling each other directly, enabling independent scaling, async processing, and loose coupling.
- Four patterns power EDA systems: event notification, event-carried state transfer, event sourcing, and CQRS, each addressing a different trade-off among payload size, consistency, and query complexity.
- Cross-service communication is where EDA gets expensive. Writing event publishers and handlers across different languages means maintaining separate integration code, DTOs, and serialization logic for every service connection, none of which is business logic.
- Graftcode replaces the protocol layer responsible for publishing and handling events. Developers configure the broker connection and topic in GraftConfig rather than writing integration code, and the same configuration switches between environments without any code change.
- EDA works best when paired with schema registries, idempotent consumers, dead letter queues, and distributed tracing, and it's the wrong choice entirely for latency-critical operations, simple CRUD systems, or small teams where broker overhead outweighs the benefit.
Modern software systems are built around things happening: a payment clears, an order ships, a sensor threshold trips. Handling those moments cleanly is the core challenge of distributed system design. Event-driven architecture (EDA) is the approach most teams reach for: instead of services calling each other directly, they publish events and react to them independently.
EDA solves coupling and scalability well. But it raises a problem most teams underestimate: writing event publishers and handlers across different languages and services still requires integration code, DTOs, and serialization logic that has nothing to do with business logic, and all of it compounds as the system grows.
This guide covers EDA from the ground up: what it is, the four core patterns, how cross-service communication works in practice, where the integration complexity accumulates, and how to eliminate it.
[2]What is an event-driven architecture
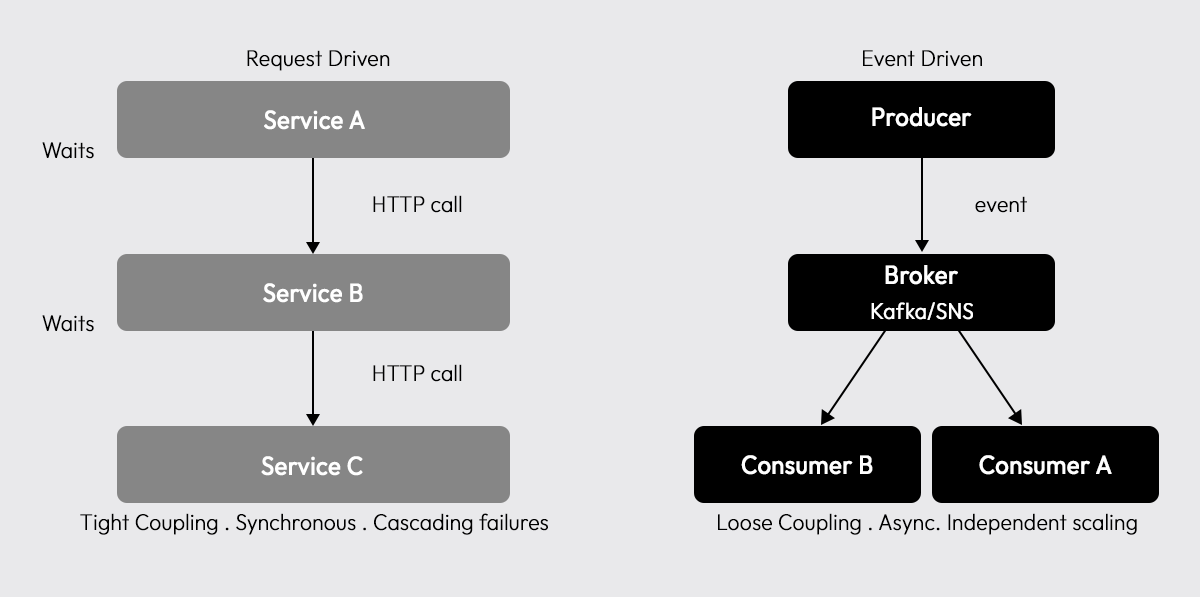
Event-driven architecture is a design approach where services communicate by publishing and consuming events, records of things that have happened, rather than calling each other directly.
The difference from request-driven architecture comes down to coupling:
- Request-driven: Service A calls Service B and waits. A must know where B is. If B is slow, A is slow. If B is down, A fails.
- Event-driven: Service A publishes an event. A doesn't know who's listening. Consumers react independently, asynchronously, on their own schedule.
Every EDA system has three roles:
| Role | Responsibility | Example |
|---|---|---|
| Producer | Emits events when state changes | Payment service emitting payment.completed |
| Broker | Receives, stores, and routes events | Kafka topic, AWS SNS, RabbitMQ exchange |
| Consumer | Subscribes and reacts to events | Notification service, inventory updater, analytics pipeline |
EDA is the right fit when:
- Multiple downstream services need to react to the same state change
- Services should be independently deployable and loosely coupled
- The system needs a full audit trail of what happened and when
- Workloads are async and don't require an immediate response
EDA is the wrong fit when:
- Operations require a synchronous, low-latency response (auth checks, real-time inventory lookups)
- The system is a simple CRUD app with no fan-out requirements
- The team is small and broker overhead outweighs architectural benefit
Understanding what EDA is and isn't sets the foundation for the patterns that actually power it.
[3]The four patterns that power event-driven systems
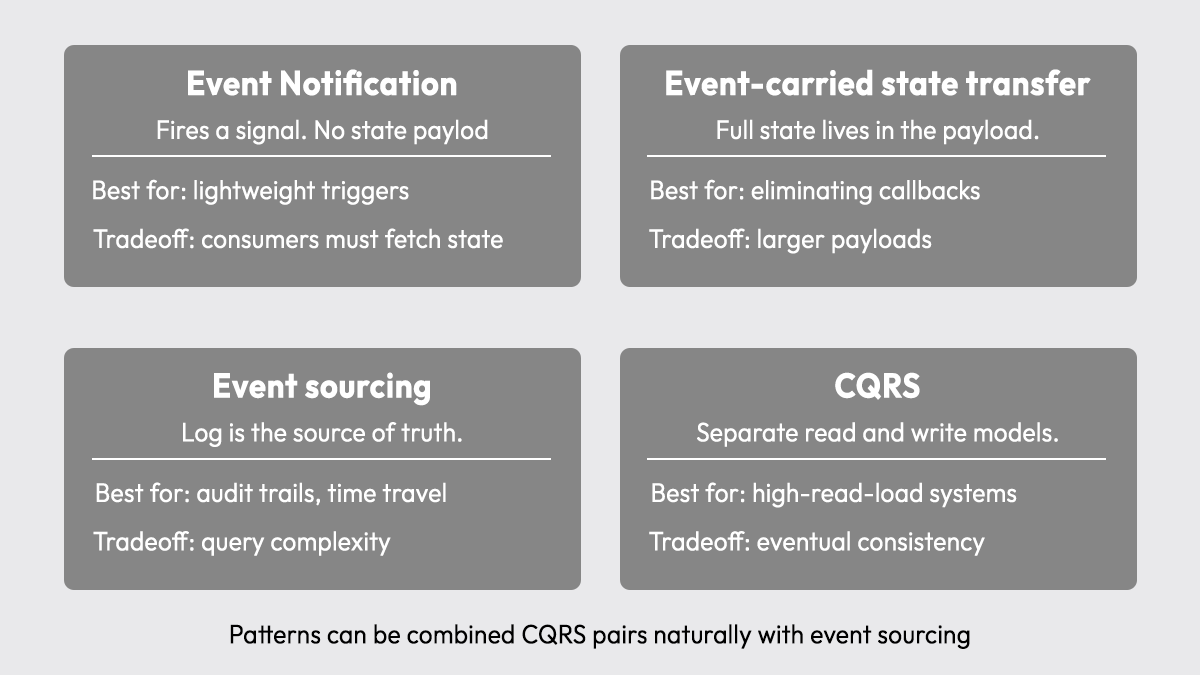
EDA isn't a single pattern; it's a family of approaches that sit on a spectrum from simple to complex. Real systems typically combine two or more of them, so understanding each one individually matters before applying them together.
Event notification keeps payloads lightweight
Event notification is the simplest pattern. A producer emits a small signal, "this thing happened", with minimal payload. Consumers receive the notification and fetch any additional state they need independently.
- Best for: Triggering downstream reactions when consumers can retrieve state on their own
- Tradeoff: Consumers must make a follow-up call to the source, which reintroduces some coupling
Example: A order.placed event carries only the order ID. The fulfillment service receives it, then queries for the full order details separately.
Event-carried state transfer eliminates downstream callbacks
Event-carried state transfer embeds the full relevant state inside the event payload. Consumers get everything they need from the event itself; no follow-up call required.
- Best for: Consumers who need to act immediately on the complete state change
- Tradeoff: Larger payloads; schema changes affect every consumer simultaneously
Example: A order.placed event carries the full order, items, quantities, shipping address, and customer ID. The fulfillment service processes it entirely from the event payload.
Event sourcing makes the log the source of truth
Event sourcing stores every state change as an immutable event in an append-only log. The current state is derived by replaying the event history; the log is the source of truth, not a database row.
- Best for: Systems requiring full audit trails, time-travel queries, or the ability to rebuild state from scratch
- Tradeoff: Querying the current state requires replaying or projecting events; schema versioning needs discipline
Example: A bank account balance is not stored as a number. It's calculated by replaying all deposited and withdrawn events from account creation.
CQRS separates read and write models for scalability
CQRS (Command Query Responsibility Segregation) splits the write model, commands that change state, from the read model, projections optimized for queries. Write operations emit events; read models are built from those events.
- Best for: Systems where read and write access patterns differ significantly, especially high-read-load services
- Tradeoff: Eventual consistency between write and read models; more infrastructure to maintain
CQRS pairs naturally with event sourcing: commands produce events, events update read-model projections.
With the patterns established, the next layer is what actually happens between services at runtime when an event fires.
[4]How cross-service communication works inside EDA systems
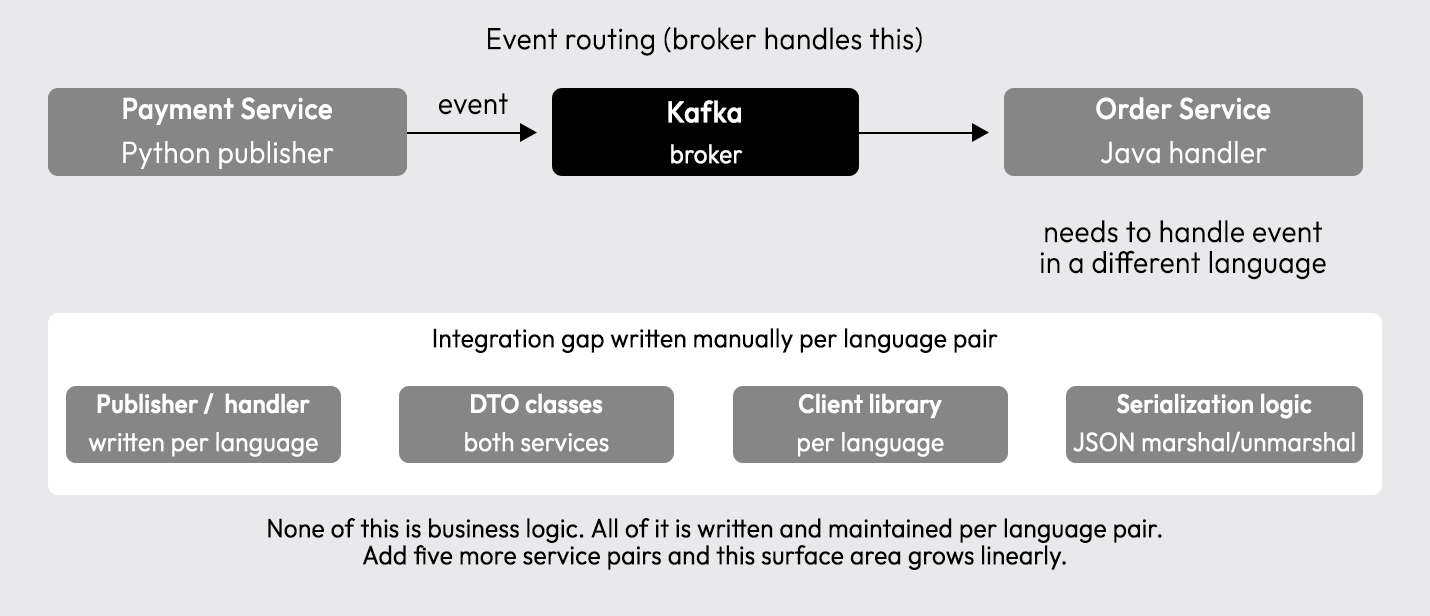
Understanding EDA patterns is one thing. Understanding what happens between services after an event fires is where real complexity surfaces.
A typical event flow looks like this:
- A Python payment service emits
payment.completedto a Kafka topic - Kafka routes the event to subscribed consumers
- A Java order service consumes the event and marks the order fulfilled
Writing publishers and handlers across these services in different languages is where the integration complexity starts. Each connection requires:
- An event publisher or handler written in the service's language
- A client library in the calling service's language
- DTO definitions matching the event schema on both sides
- Serialization logic (JSON marshaling/unmarshaling) in both services
- Manual versioning discipline when the schema changes
- Updates to every handler when the event structure evolves
In a five-service system with four language pairs, that's a significant ongoing maintenance surface. And none of it is business logic. That surface is the integration layer, and it's where most of the complexity compounds.
[5]Why does the integration layer get expensive fast
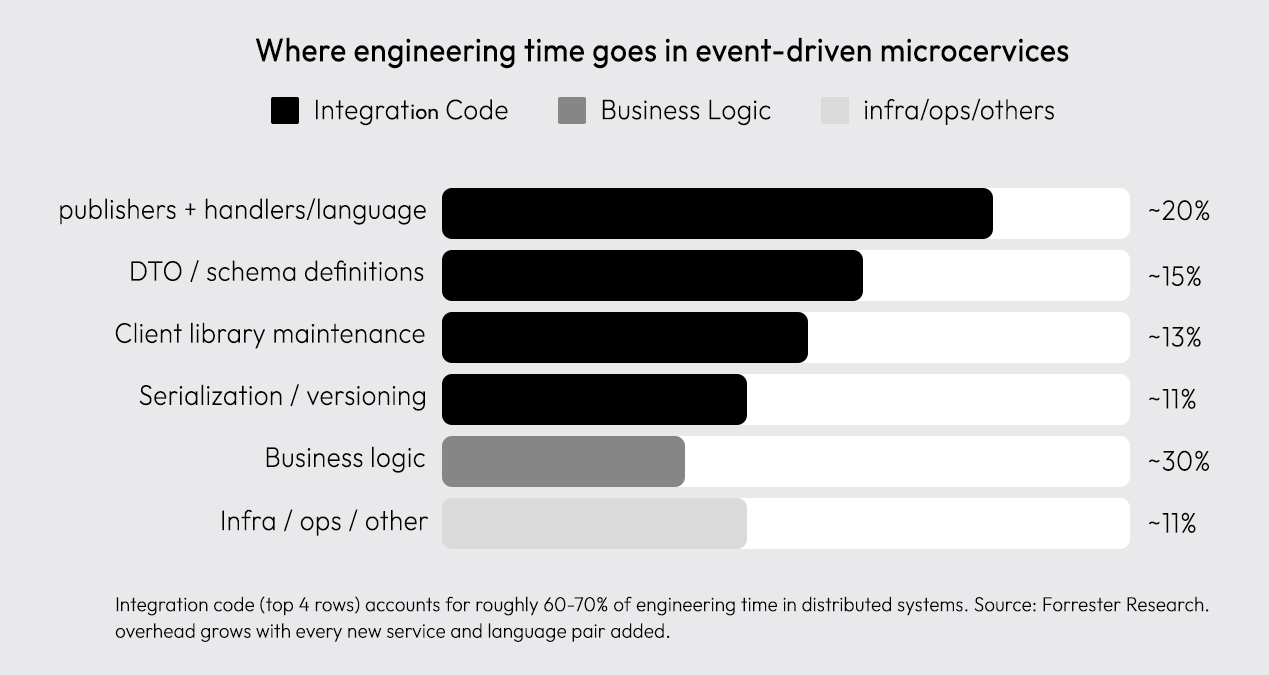
The integration layer isn't unique to EDA; it's the cost of distributed systems generally. But EDA makes it worse because there are more services, more language diversity, and more connection points than a traditional layered architecture.
Forrester Research puts the number at roughly 70% of development work being integration code, not product features, not business logic. Just wiring.
The specific problems that compound:
- Schema drift: A producer updates a field name. Consumers break silently at runtime, not at compile time.
- Cross-language serialization: Every language pair needs its own DTO mapping. Java-to-Python is different from Java-to-Node.js, which is different from Go-to-Ruby.
- Client library churn: When an event schema changes, every dependent handler needs an updated client. Nothing propagates automatically.
- Versioning overhead: Breaking changes require coordinated deploys across teams. The coordination cost is often higher than the cost of the change itself.
- Boilerplate at scale: In a system with 20 services, the integration layer isn't a cost center; it's close to a full-time job.
Each new service and language pair added to the system multiplies this surface. This is the integration tax, and the question is whether it needs to exist at all.
[6]How Graftcode eliminates the integration layer from EDA systems
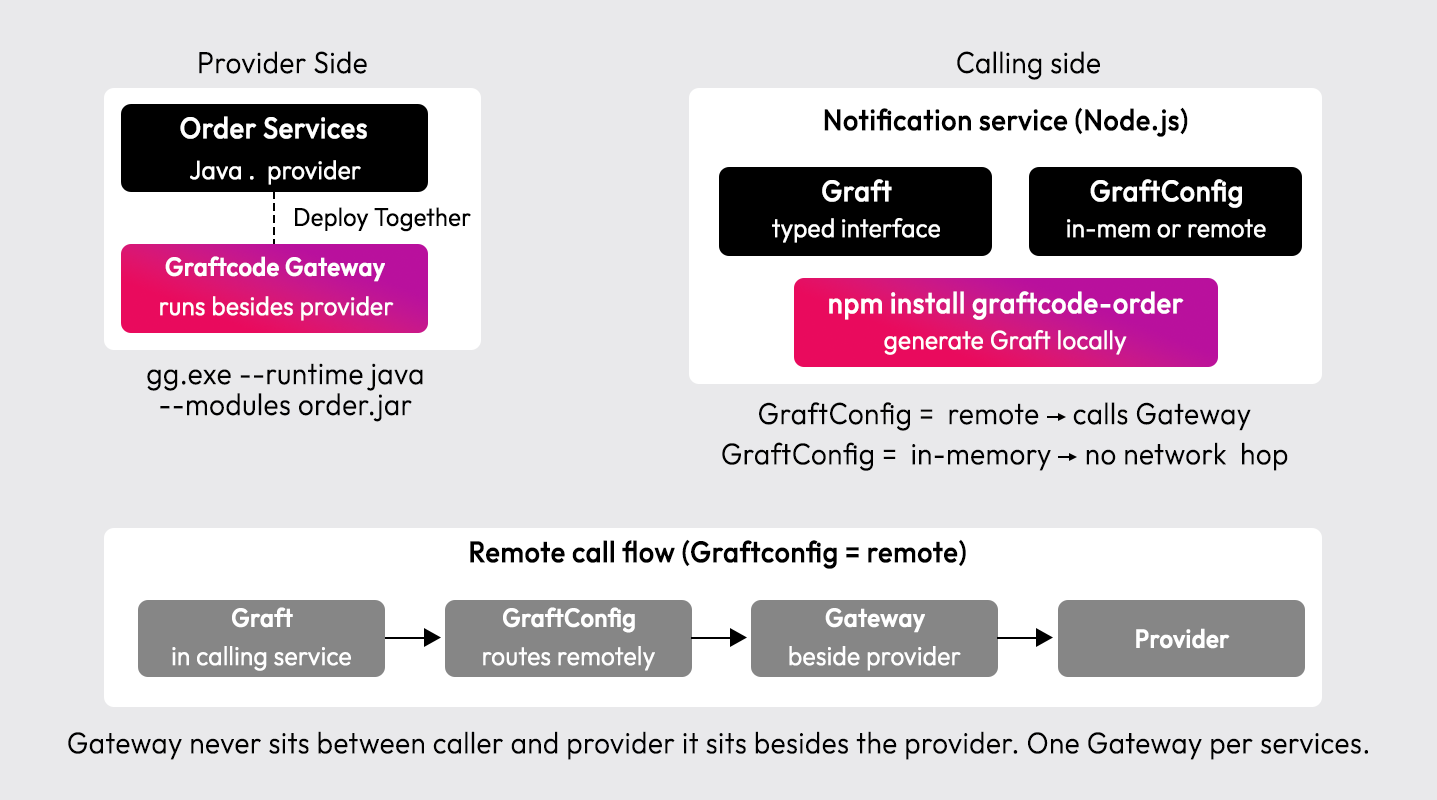
Graftcode is a cross-runtime communication layer. Instead of writing event publishers and handlers manually, defining DTOs, and maintaining client libraries across language pairs, a developer installs a strongly typed Graft via their standard package manager. Graftcode handles the publishing, consuming, and handling layer, the broker underneath still routes the messages, but the integration code disappears.
The protocol underneath is Hypertube, which uses native runtime integration and binary messaging instead of text-based JSON/XML serialization. Service interactions run up to 70% faster than conventional integration approaches, with one-eighth the CPU consumption of equivalent gRPC or HTTP-based messaging workloads.
Three steps replace the entire integration layer
Step 1: Run the Graftcode Gateway alongside your service
The Graftcode Gateway is a lightweight, dependency-free native binary that loads your service's runtime and exposes its public methods to callers. It is not a proxy, not middleware, and not a traffic interceptor; it runs beside your service and makes its interface callable without any endpoint definitions, protobuf files, or annotations.
# Download the Graftcode Gateway binary (Linux example)# Available at: https://github.com/grft-dev/graftcode-gateway/releases/chmod +x graftcode-gateway# Start the Gateway — it loads your Java service runtime and exposes public methods./graftcode-gateway \--project-id your-project-id \--runtime jvm \--module ./order-service.jar# Or run via Docker alongside your servicedocker run --rm \-v $(pwd)/order-service.jar:/app/order-service.jar \-p 9000:9000 \graftcode/gateway:latest \--project-id your-project-id \--runtime jvm \--module /app/order-service.jar
Once the Gateway starts, it analyzes all public classes and methods in order-service.jar and builds a Unified Graft Model, a language-agnostic representation of the callable interface. That model is what Graftcode uses to generate typed clients for any consuming service, in any supported language, on demand.
Step 2: Install a Graft in the calling service
From the calling service, point your package manager at the Graftcode registry for your project and install the Graft. The registry URL encodes your project ID, this is how Graftcode knows which Gateway's Unified Graft Model to generate the client from.
# Add the Graftcode registry to your npm config# Registry URL format: https://grft.dev/<project-id>__graftcodenpm config set @graft:registry httpsfrom inference_service import InferenceService://grft.dev/your-project-id__graftcode# Install the Graft — package name encodes the source ecosystem and module name# Format: @graft/<source-ecosystem>-<ModuleName>npm install @graft/jvm-OrderService
The Graft is a first-class npm package. It mirrors the Java service's public interface precisely, method signatures, argument types, return types, and errors, all expressed in TypeScript-native types. If the Java service's public interface changes, the Graft package updates and the incompatibility surfaces at compile time rather than at runtime. Teams control when to apply those updates; they appear as standard package version bumps.
Step 3: Configure GraftConfig and call methods
GraftConfig controls whether a Graft call runs in-memory or connects to a deployed Gateway, this is a configuration change, not a code change. The same method calls work in both modes.
import { GraftConfig, OrderService } from "@graft/jvm-OrderService";// Remote mode (staging/production) — point to the deployed GatewayGraftConfig.host = "tcp://order-service:9000";// In-memory mode (local dev) — set mode explicitly, no network hop// GraftConfig.mode = "in-memory";// Same calling code works in both modes — no other changes requiredconst service = new OrderService();// Strongly typed — return type inferred from the Java method signatureconst order = await service.getOrderById(orderId);// Complex return types are Graft references — subsequent calls also execute remotelyconst invoice = await order.generateInvoice({ currency: "USD" });console.log(`Order total: ${invoice.totalAmount}`);
GraftConfig controls the mode, point it to the Gateway for remote calls, or set it to in-memory for local development. The business logic and method calls stay identical either way.
What Graftcode replaces in a real EDA system
| Without Graftcode | With Graftcode |
|---|---|
| Write event publishers per language | Publishing handled by the Graftcode layer |
| Write event handlers per service | Handlers auto-generated via Graft |
| Write DTO classes per language pair | Strongly typed client auto-generated |
| Manually version schemas across teams | Interface changes surface as package updates |
| Write serialization/deserialization code | Handled by Hypertube binary protocol |
| Maintain separate client libraries | One install command per dependency |
Where Graftcode fits in the EDA stack
Graftcode handles the publisher and handler layer. The broker, Kafka, RabbitMQ, and EventBridge still route messages and manage topics. What Graftcode removes is the integration code that developers would otherwise write to publish to and consume from those topics. The developer specifies the broker address and topic name in GraftConfig. Graftcode takes care of the rest.
****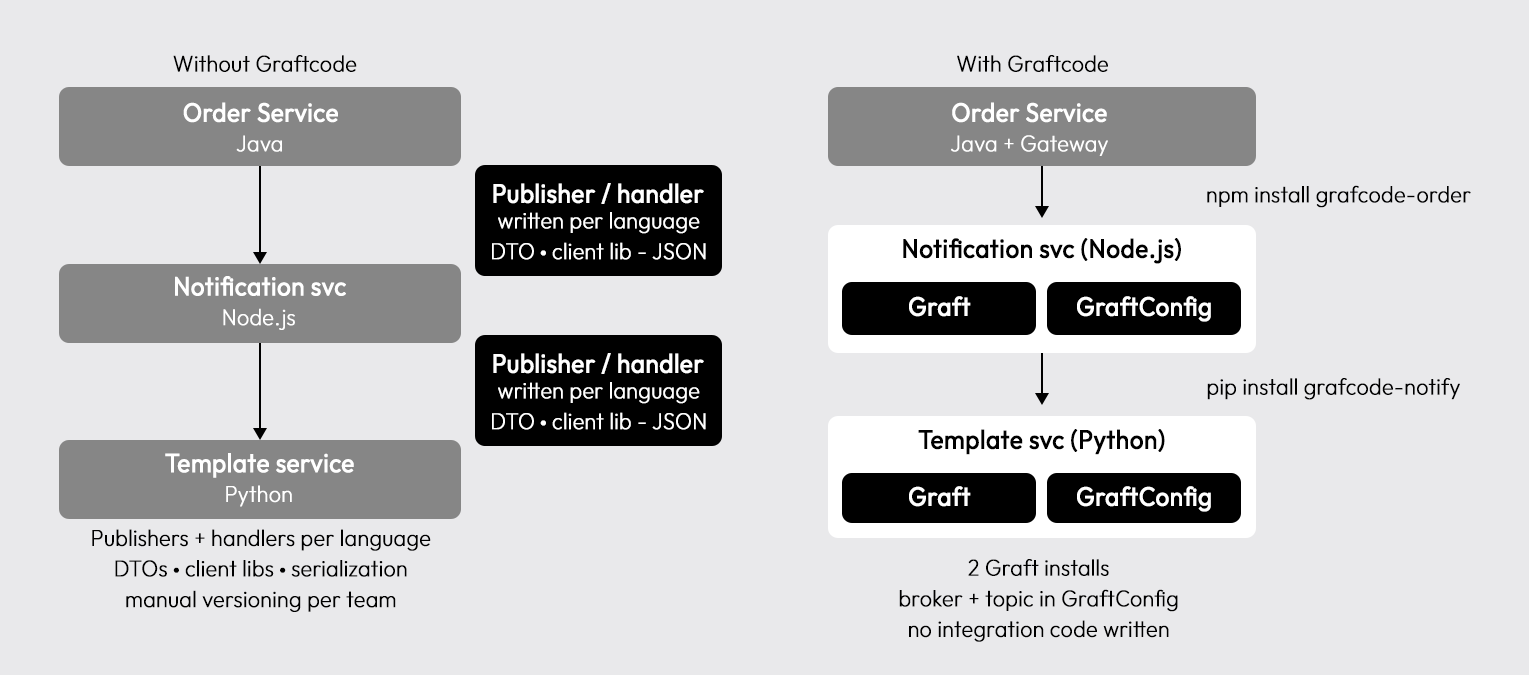
Concrete example: a three-service payment flow:
- Python payment service publishes
payment.completedto a Kafka topic - Java order service consumes the event and marks the order fulfilled
- Node.js notification service consumes the same event and sends a confirmation email
Without Graftcode: Publishers and handlers written separately in Python, Java, and Node.js, DTO classes per service pair, serialization logic in every service, and manual version coordination across three teams.
With Graftcode: Three Graft installs. Publishing and handling are configured via GraftConfig, broker address, and topic name. No integration code written. The broker still routes the messages.
Performance: What Hypertube delivers

| Protocol | Speed vs REST | CPU vs REST |
|---|---|---|
| REST (baseline) | 1× | 1× |
| gRPC | ~2–3× | ~4× lower |
| Graftcode (Hypertube) | Up to 70% faster | Up to 8× lower |
The gap comes from native runtime integration. Hypertube connects directly to target runtime native layers; it doesn't wrap HTTP or rely on text-based wire formats. The result is measurably lower overhead at both the network and CPU levels.
Language and ecosystem support
Graftcode supports over 20 programming languages across all major package managers, npm, pip, NuGet, Maven, RubyGems, Go Modules, and others. Services written in Python, Java, C#, Node.js, Go, Ruby, PHP, and Kotlin can communicate through Grafts without any language-specific integration code. It works across AWS, Azure, GCP, Kubernetes, and Docker.
[7]Best practices for keeping event-driven systems maintainable
Building a working EDA system is one thing. Keeping it maintainable at scale requires deliberate choices across schema management, failure handling, and observability.
Schema management
- Use a schema registry (Confluent Schema Registry, AWS Glue) to enforce contracts between producers and consumers
- Version event schemas explicitly,
v1,v2, and support backward compatibility during migrations - Treat schema changes like API changes: communicate them, version them, deprecate old versions on a timeline
Idempotency: Consumers in EDA systems receive events with at-least-once delivery guarantees. Design every consumer to handle duplicate events safely. The cleanest approach is to use a unique event ID to deduplicate at the consumer before taking action.
Dead letter queues: Failed events should route to a dead letter queue (DLQ) rather than disappearing or blocking the main queue. A spike in DLQ volume is usually the first signal of a downstream problem; monitor them actively.
Distributed tracing: Async systems make debugging hard. A request crossing four services via events produces no single stack trace. Distributed tracing tools (OpenTelemetry, Jaeger, Datadog APM) with trace context propagation, a correlation ID passed through every event payload, let teams reconstruct the full flow from logs.
Domain event ownership: Each event type should have a clear owning team, responsible for schema, versioning, and backward compatibility. Without ownership, schema drift becomes inevitable.
Separation of business logic from integration code: Business logic and integration code shouldn't live in the same layer. Graftcode makes this easier to maintain in practice, service methods express business intent, and the communication layer handles transport automatically.
[8]When event-driven architecture is the wrong choice
EDA has real overhead: a broker to operate, consumers to deploy, schemas to manage, and eventual consistency to reason about. For some systems, that cost isn't worth it.
Skip EDA when:
- Latency is critical. Operations that require sub-millisecond synchronous responses, auth token validation, and real-time inventory checks don't fit into async event flows.
- The system is simple. A CRUD API with a single downstream database and no fan-out requirements gains nothing from a broker in the middle.
- The team is small. EDA adds operational surface area. For a two-engineer team, running Kafka or managing EventBridge rules may outweigh any architectural benefit.
- Consistency requirements are strict. Systems where two operations must succeed or fail together are harder to implement correctly in an async model.
[9]Conclusion
Event-driven architecture changes how distributed systems handle state changes, from tight synchronous calls to loosely coupled, reactive flows. The patterns (notification, state transfer, event sourcing, CQRS), the broker, and the cross-service communication layer each need to fit together for the system to hold up at scale.
The broker handles routing. The patterns handle semantics. What's left, the publishers, handlers, and integration code that wire services together across language boundaries, is where the integration tax lands. Eliminating that layer through runtime bridging is what makes EDA genuinely sustainable as the system grows.
[10]FAQ
1. How does event-driven architecture handle eventual consistency across microservices?
Eventual consistency is a core tradeoff in EDA. When a producer emits an event and multiple consumers update their own data stores independently, there's no guarantee all services reflect the same state at the same instant. The standard approach is to design consumers to be idempotent, use event versioning to track causal order, and implement compensating transactions (sagas) for operations that span multiple services. Tools like Kafka's log compaction help consumers catch up after downtime without losing state.
2. What is the difference between event sourcing and a traditional database with a changelog?
A traditional changelog (like MySQL binlog) is a side effect of writes; it records what changed but isn't the system of record. Event sourcing inverts this: events are the primary record, and the current state is a derived projection. This means you can rebuild state at any point in time, create new projections retroactively, and audit exactly what happened and why, none of which are reliable with a changelog alone.
3. How does Graftcode's Hypertube protocol differ from gRPC in cross-service communication?
gRPC uses HTTP/2 as its transport layer with protobuf serialization. Protobuf definitions are written as .proto text files, but the wire format is binary. Graftcode also uses binary messaging over Hypertube; the difference is that Graftcode generates the interface directly from public method signatures with no .proto files, no manual code generation step, and no schema registry. Incompatibilities surface at compile time when the interface changes.
4. Can event-driven architecture work with monolithic applications, or does it require microservices?
EDA doesn't require microservices. A monolith can publish events internally using an in-process event bus (like Spring's ApplicationEventPublisher or Node's EventEmitter) and consume them in separate modules. The benefit is the same; decoupled modules react to state changes without direct method calls. When the monolith later gets split into services, the event contracts are already defined and the migration is mostly an infrastructure change, not a logic rewrite.
5. How does Graftcode handle event publishing and consuming without writing integration code?
The developer specifies the broker address and topic name in GraftConfig. Graftcode handles the publishing and consuming layer, connecting to the topic, receiving messages, and routing them to the appropriate handler. No publisher or handler code needs to be written manually. The broker still manages routing and fan-out; Graftcode removes the integration layer that sits between the broker and the business logic.
/WRITTEN BY