Microservices Architecture: A Complete Guide for Backend Engineers

/TABLE OF CONTENTS
/ARTICLE
/ARTICLE
[1]TL;DR
- Microservices architecture decomposes a system by business capability, giving teams independent deployability, fault isolation, and scaling flexibility, but at the cost of real operational complexity.
- Good microservices design is defined by bounded contexts, loose coupling, decentralized data ownership, and building for failure from day one, not just splitting code into smaller repos.
- Inter-service communication choices (REST, gRPC, message queues, service mesh) have significant trade-offs in performance, reliability, and operational overhead that compound as the system grows.
- Patterns like API Gateway, Circuit Breaker, Bulkhead, and Strangler Fig are not optional polish; they are the structural layer that keeps a microservices system from collapsing under its own complexity.
- The highest underestimation in microservices is the API plumbing tax: 30-40% of engineering time lost to integration code, DTO drift, and SDK versioning, which Graftcode eliminates by letting services call each other's public methods as strongly-typed Grafts with zero hand-written integration code.
Software architecture has always reflected how teams build and ship. For most of the web's early history, the dominant model was simple: one codebase, one database, one deployable unit. That worked, until systems grew complex enough and teams scaled large enough that a single deployable unit became the bottleneck. Deployments got risky. A bug in one module could take down the entire product. Scaling meant scaling everything, even the parts that didn't need it.
Microservices emerged as a response to that friction, and a decade later, engineers are still debating how to get them right. The problems have evolved, too. It's not just about splitting a Rails monolith anymore. Teams are now building systems in which LLM inference services, agent orchestrators, RAG pipelines, and traditional backend services must communicate reliably. The integration surface has grown larger, the failure modes more complex, and the cost of getting boundaries wrong higher.
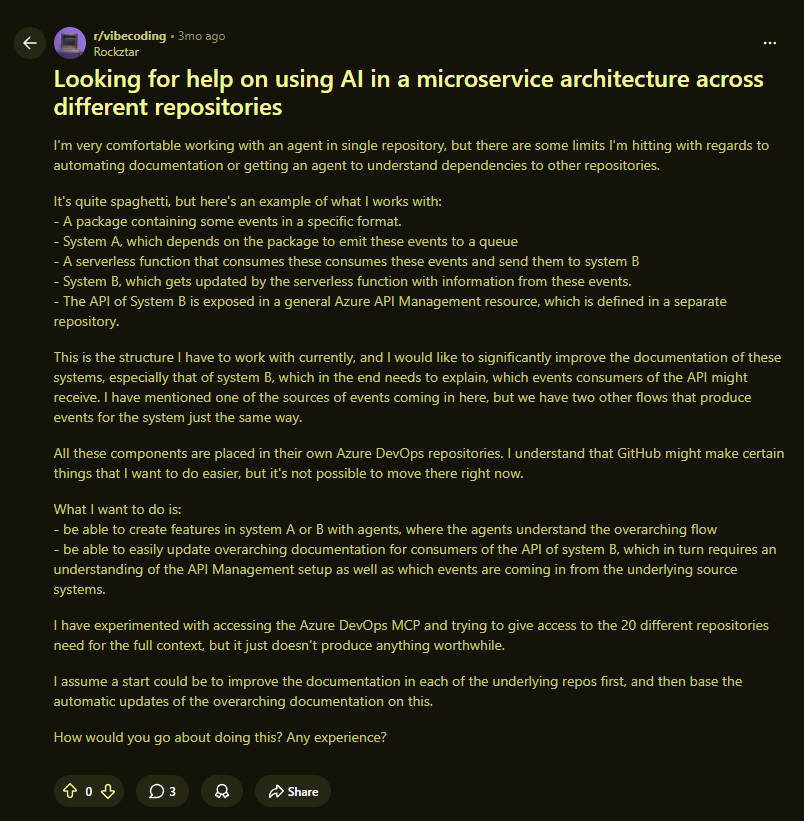
The thread above is from r/vibecoding, engineers asking how to wire AI components into a microservices architecture without the whole thing becoming unmanageable. The pain points are consistent: inter-service auth overhead, debugging failures across service boundaries, and keeping integration contracts in sync as services evolve. These aren't new problems, but they're hitting harder now. This guide covers what microservices actually involve in practice: where boundaries should be drawn, how services communicate, the patterns that keep distributed systems stable, and the operational costs most teams underestimate until they're already paying them.
[2]What Is Microservices Architecture and Why Did It Replace the Monolith?
Microservices architecture is a design approach in which a system is broken down into small, independently deployable services, each responsible for a specific business capability. Each service runs its own process, exposes its own interface, and can be deployed, scaled, and updated without touching the rest of the system.
The distinction that matters most is how you draw the boundaries. Splitting by technical layer into a "database service," a "logging service," and an "auth service" that everything else calls creates implicit coupling at the infrastructure level. Every service that depends on your central auth service is now runtime-dependent on it. If it goes down, everything that calls it goes down with it. If its interface changes, every consumer breaks. A well-designed microservice owns a complete vertical slice of the domain: its own data, its own business logic, and its own interface, with no shared infrastructure that other services depend on.
To make this concrete: a developer productivity platform might be split into a code execution service, a session management service, a context retrieval service, and an LLM inference service. Each can be scaled independently; the inference service needs GPUs, the session service needs low-latency storage, and the execution service needs sandboxed compute. Each can fail independently. Each can be updated without a coordinated release. That's the actual payoff of microservices, not cleaner diagrams, but independent failure domains and independent scaling budgets.
When The Monolith Stops Being Enough
The engineers in that Reddit thread weren't debating microservices vs monolith philosophically; they were hitting specific walls. One team's LLM inference service was getting starved of resources because it shared infrastructure with the rest of the application. Another couldn't update their RAG pipeline without a full redeploy. A third had inter-service auth so tangled that adding a new agent tool required changes across four services.
These are the signals that a monolith is becoming the bottleneck:
- A single slow or resource-heavy component, a GPU inference call, or a heavy data transformation job, is degrading response times across the entire application
- Different parts of the system need to scale at different rates, but can't because they're packaged together
- Multiple teams are stepping on each other's deployments because everything ships as one unit
- A failure in one subsystem, a third-party API call, or a background job takes down unrelated functionality
None of these are solved automatically by microservices. They're solved by correctly scoped service boundaries that give each component its own scaling budget, failure domain, and deployment cycle. Microservices are the mechanism. The boundary decisions are the actual work.
[3]How to Draw Service Boundaries That Actually Hold Up
Most microservices architectures that end up as a mess got there not because the team chose the wrong technology, but because they drew the wrong boundaries from the start. The hard part isn't splitting a system into smaller services; it's splitting it in a way that gives each service genuine independence, not just a separate codebase with all the same hidden dependencies.
Why Splitting By Technical Layer Creates Distributed Coupling
The most common boundary mistake is splitting by technical concern rather than by business capability. A "notification service" that only sends emails but has no ownership over when or why they're sent isn't a real service boundary; it's a shared utility with a network hop in front of it. The calling service still owns the logic. The notification service just executes it. You've added network latency and a new failure point without gaining any independence.
A real service boundary means the service owns the full vertical slice: the decision logic, the data it needs to make that decision, and the interface it exposes to the outside world. Nothing else reads its database. Nothing else makes its decisions. Here's what that looks like across three different system types:
SaaS backend: an auth service that handles token issuance, validation, and revocation end-to-end. A billing service that owns subscription state, payment processing, and invoice generation. A notifications service that owns the decision of when to notify, the template logic, and the delivery mechanism. Each service is self-contained. None of them shares tables or calls each other's internal APIs.
AI/agentic system: a code generation service that owns the prompt strategy, context retrieval, and model call, exposing only the generated output. A tool execution service that owns a sandboxed runtime, execution state, and result storage. An orchestrator that owns workflow state and task sequencing, communicating with other services through events rather than direct calls. The boundary is drawn around what changes together, not around what sounds like a clean technical layer.
Data pipeline: an ingestion service that owns raw data intake and schema validation. A transformation service that owns normalization and enrichment logic. A serving service that owns the query interface and caching layer. Each stage has its own storage and its own deployment cycle. A schema change in ingestion doesn't require a coordinated redeploy of the serving layer.
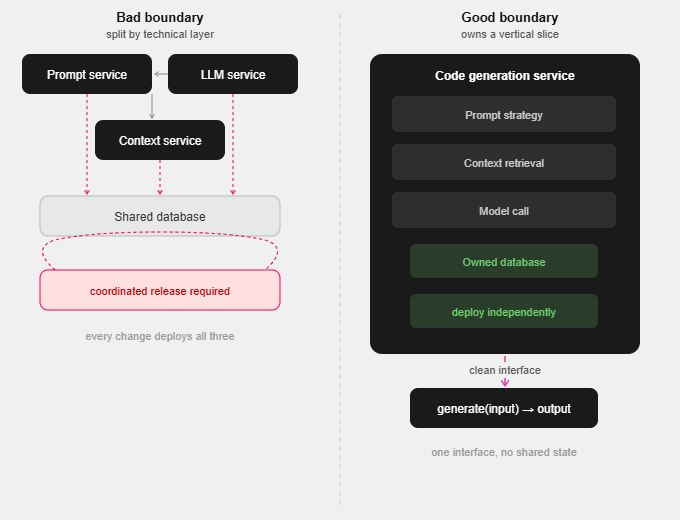
The left side shows three services split by technical concern; each change requires coordinating all three deployments, and they all read from the same database, making the coupling invisible but real. The right side shows a single service that owns the full vertical slice, including prompt logic, context retrieval, and the model call, all live within one deployment boundary, backed by one owned database, exposing one clean interface to the outside world.
Why Shared Databases Are The Most Common Source Of Hidden Coupling
Every service should own its own data store. No two services should read from or write to the same database table. This is consistently violated in practice because early on, sharing a database feels like the pragmatic shortcut, and it is, until Team A renames a field in a shared table and silently breaks every query Team B runs against it. At that point, you have the operational complexity of microservices with none of the independence.
In an agentic system, this compounds further. If your agent orchestrator and tool execution service share a state table to track in-progress tasks, a schema migration by either team breaks the other. The fix is event-based communication: the orchestrator owns the task queue, the executor owns the execution log, and they stay decoupled through events rather than shared rows.
The Coordination Tax That Tells You Your Boundary Is Wrong
The deployment test is the most reliable way to validate a service boundary: a correctly scoped service should be deployable without requiring a coordinated release with any other team or service. If deploying Service A requires a simultaneous deploy of Service B because they share a schema, a contract, or an assumption about each other's internal state, the boundary is wrong, the services are coupled, just distributed across two codebases, which is worse because the coupling is now invisible.
The r/vibecoding thread surfaces this exact failure mode. One team built an AI microservice architecture where the agent orchestrator, the tool registry, and the LLM gateway all needed to be deployed together every time the tool interface changed, three services with no actual independence because the boundary was drawn around deployment units, not around capabilities.
Designing For Failure From The Start
A correctly bounded service can still take down its consumers if it doesn't account for unavailability. Every service needs timeouts on every outbound call, retry logic with exponential backoff, circuit breakers that stop sending requests after repeated failures, and graceful degradation that returns a safe default rather than propagating a 500. These aren't implementation details; they're boundary requirements. A service that doesn't handle its own failure surface correctly violates the independence it was designed to provide.
The patterns for implementing this, circuit breakers, bulkheads, and timeouts, are covered in later sections.
Once your boundaries are correctly drawn and your services are built to handle failure independently, the next challenge is how they communicate, and what that communication costs as the system scales.
[4]How Microservices Communicate with Each Other
In a monolith, one module calls another through an in-process function call, fast, strongly typed, and if something breaks, the stack trace tells you exactly where. In a microservices system, that same call crosses a network boundary. Latency becomes variable. Failures become partial. Debugging becomes distributed.
The decisions you make here have direct production consequences. When your LLM inference service times out mid-request, does your agent orchestrator retry, fail fast, or queue the job? When your tool execution service is under load, does the calling service back off or pile on more requests? Getting these wrong is one of the most consistent sources of production incidents in distributed systems.
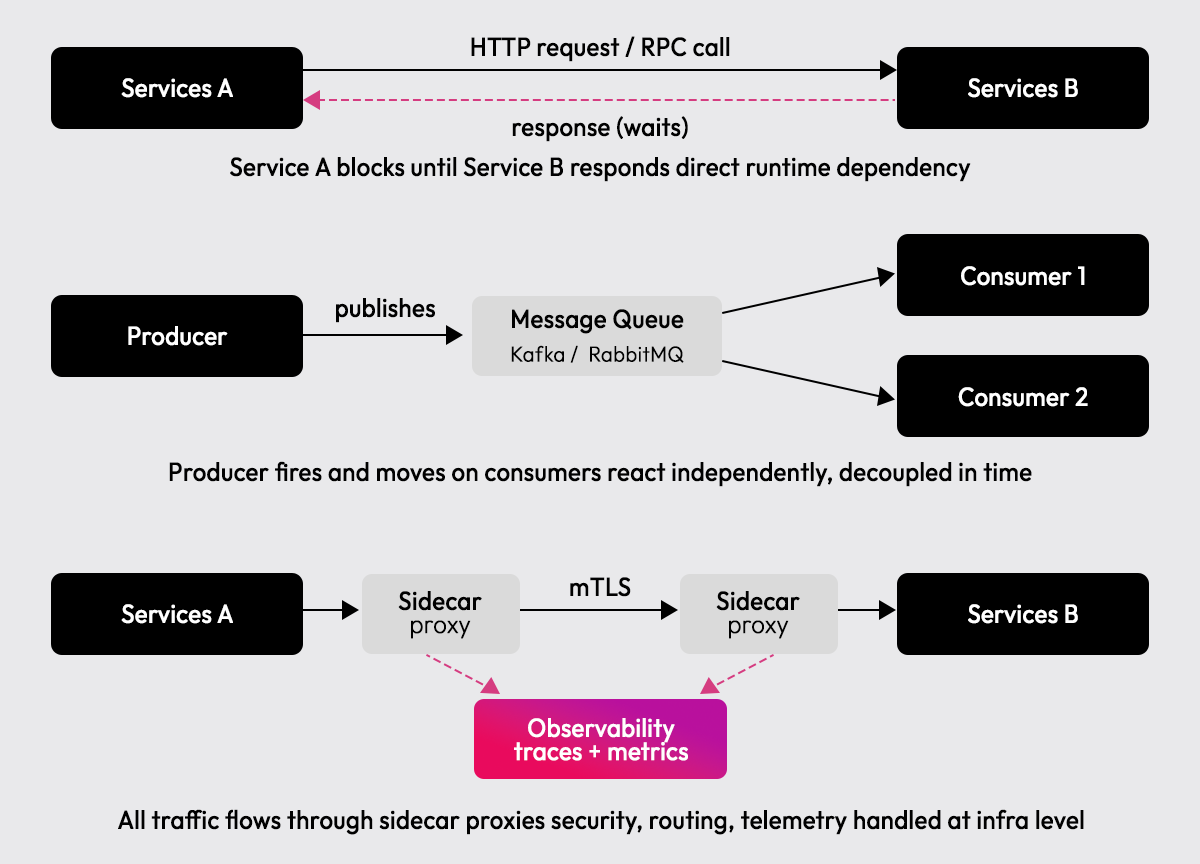
Synchronous Communication
Synchronous communication means Service A sends a request and waits for Service B to respond before continuing. It mirrors how in-process function calls work, but introduces a direct runtime dependency; if Service B is slow, Service A is slow; if Service B is down, Service A fails.
REST over HTTP is the most common approach. Easy to implement, human-readable, and works across virtually every language and toolchain. The downside is that it's loosely typed by default, without an enforced schema; API drift is a real risk. One team renames a field in their response payload, and the consuming service starts throwing NullPointerExceptions in production with no compile-time warning.
gRPC uses Protocol Buffers for a strongly typed, binary-serialized contract. The .proto file is an enforced schema; if a field changes, the consuming service fails at compile time, rather than at runtime. It's significantly faster than REST and better suited for high-throughput internal service communication where both sides of the call are under your control.
| Property | REST | gRPC |
|---|---|---|
| Protocol | HTTP/1.1 or HTTP/2 | HTTP/2 |
| Payload format | JSON (text) | Protocol Buffers (binary) |
| Typing | Loose (optional via OpenAPI) | Strongly typed |
| Performance | Moderate | High |
| Browser support | Native | Limited |
| Best for | Public APIs, external clients | Internal service communication |
Here's what the same call looks like in both:
# REST -- calling a context retrieval serviceimport requestsresponse = requests.post("https://context-service/retrieve",json={"query": user_query, "top_k": 5},headers={"Authorization": f"Bearer {token}"})chunks = response.json()["chunks"] # no type safety, no guarantee this field exists# gRPC -- same call with a typed contractimport grpcfrom context_pb2_grpc import ContextServiceStubfrom context_pb2 import RetrieveRequestchannel = grpc.insecure_channel("context-service:50051")stub = ContextServiceStub(channel)response = stub.Retrieve(RetrieveRequest(query=user_query, top_k=5))chunks = response.chunks # typed, guaranteed by the proto contract
The gRPC version surfaces a missing field or type mismatch at build time. The REST version throws a KeyError at 2 am in production.
Asynchronous Communication
Asynchronous communication means Service A publishes a message and moves on; Service B can be slow, restarting, or temporarily unavailable, and Service A keeps running. Kafka, RabbitMQ, and AWS SQS are the primary tools.
In an agentic system, this pattern maps directly to how multi-step workflows should be structured. An orchestrator publishes a tool.invoked event, the tool execution service picks it up, processes it, and publishes a tool.completed the event back. Neither service is blocked waiting on the other. Each step runs at its own pace, and failures in one step don't cascade into the others.
The trade-off is observability. Debugging asynchronous flows is significantly harder; there's no single stack trace to follow across a publish and a consume. You need distributed tracing with correlation IDs threaded through every event, and careful dead-letter queue management to catch messages that fail processing without silently disappearing.
Service Mesh
As the number of services grows, managing cross-cutting concerns, mTLS, retries, circuit breaking, load balancing, and observability at the application level becomes repetitive and error-prone. A service mesh moves this logic out of application code and into a dedicated infrastructure layer via sidecar proxies injected alongside each service.
Tools like Istio and Linkerd handle security, routing, and telemetry automatically without requiring changes to service code. The operational overhead is real, though; a service mesh is typically worth it only once you're managing dozens of services. For smaller systems, the complexity it adds outweighs what it saves.
Which Communication Pattern Fits Which Scenario?
| Scenario | Recommended approach | Why |
|---|---|---|
| User-facing request needing immediate response | REST or gRPC | Latency matters; a response is needed before proceeding |
| LLM inference call between internal services | gRPC | Binary serialization, typed contract, streaming support |
| Multi-step agent workflow | Async event queue | Steps don't need to block each other |
| Background processing, analytics | Message queue | Throughput over latency, consumers can scale independently |
| Large fleet needing consistent auth and observability | Service mesh | Cross-cutting concerns handled at the infrastructure level |
Understanding how services communicate gets you halfway there. The other half is knowing what to do when that communication breaks, and which patterns engineers actually reach for in production to contain failures before they cascade.
[5]The Patterns Behind Every Stable Microservices System in Production
These aren't patterns you read about and file away. They're the ones that show up repeatedly in production incidents, either because someone implemented them and they worked, or because someone skipped them and paid for it.
API Gateway
An API Gateway is the single entry point for external traffic into your microservices system. Beyond routing, it handles auth verification, rate limiting, SSL termination, and request logging, concerns you don't want reimplemented inside every service.
For AI systems specifically, the gateway is where you enforce LLM token quotas and rate limits before requests reach your inference service. A tenant hammering your API shouldn't be able to starve other users of GPU time; that enforcement belongs at the gateway layer, not inside the inference service itself. Popular implementations include Kong, AWS API Gateway, and NGINX.
Circuit Breaker
When a downstream service starts failing, a naive caller keeps retrying, holding threads open, queuing more requests, and eventually backing up the entire call chain. A circuit breaker tracks failure rates on outbound calls and, once failures cross a threshold, stops sending requests to the struggling service and fails fast instead.
The circuit moves through three states:
- Closed: requests flow normally
- Open: requests fail immediately without hitting the downstream service, giving it room to recover
- Half-open: a small number of probe requests go through to test recovery; if they succeed, the circuit closes again
Here's what this looks like in Python using tenacity:
from tenacity import retry, stop_after_attempt, wait_exponential, retry_if_exception_typeimport httpx@retry(stop=stop_after_attempt(3),wait=wait_exponential(multiplier=1, min=2, max=10),retry=retry_if_exception_type(httpx.HTTPStatusError))async def call_inference_service(payload: dict) -> dict:async with httpx.AsyncClient() as client:response = await client.post("http://inference-service/generate",json=payload,timeout=5.0)response.raise_for_status()return response.json()
Without this, a single slow inference response holds the calling service's threads open until timeout. Under load, that compounds into a full service outage. The circuit breaker contains the blast radius to the one failing dependency.
Strangler Fig
The Strangler Fig is the only reliable way to migrate from a monolith to microservices without a big-bang rewrite. In practice: put a routing layer in front of the monolith, extract one capability with clear boundaries into a standalone service, route traffic for that capability to the new service, and repeat incrementally until the monolith is hollowed out.
The monolith keeps running throughout. Each extraction is independently deployable and reversible, with no coordinated cutover or flag day. This maps directly to how Graftcode handles the monolith-to-microservice transition, which later sections cover in detail.
Bulkhead
The Bulkhead pattern prevents a resource spike in one service from starving unrelated services running on the same infrastructure. In Kubernetes, this is enforced through container resource limits:
resources:requests:memory: "512Mi"cpu: "500m"limits:memory: "1Gi"cpu: "1000m"
Without these limits, a memory leak in your inference container or a runaway background job can starve every other container on the same node, including your auth and session services that have nothing to do with the failing workload.
These patterns keep individual failures from becoming system-wide outages. But even with all of them in place, there's a category of cost that compounds silently as the system grows, one that doesn't show up in your error logs but in your sprint velocity. That's what the next section covers.
[6]The Operational Costs That Come With Every Service You Add
Every service you add to a microservices system increases the system's operational surface area. Not just the service itself, the health checks, the deployment pipeline, the observability instrumentation, the security configuration, the integration contracts with every service it talks to. These costs don't show up on day one. They accumulate quietly until the team is spending more time keeping services running and talking to each other than building the actual product.
Service discovery
In Kubernetes, service discovery is largely handled through DNS and the built-in Service abstraction. A service gets a stable DNS name, and callers use that name regardless of how many instances are running or where they're scheduled. What Kubernetes doesn't handle for you is the correctness of that registry. If a pod is terminating but hasn't finished draining connections, traffic continues to be routed to it. If a pod fails its readiness probe but hasn't been deregistered yet, callers get 503s with no clear explanation.
The parts teams get wrong are the readiness and liveness probe configurations, graceful shutdown handling, and preStop hooks. A service that doesn't implement graceful shutdown correctly will drop in-flight requests every time it restarts, which is constant in a high-churn Kubernetes environment.
lifecycle:preStop:exec:command: ["sh", "-c", "sleep 5"]readinessProbe:httpGet:path: /healthport: 8080initialDelaySeconds: 5periodSeconds: 10
Without the preStop sleep, Kubernetes removes the pod from the load balancer and sends SIGTERM simultaneously, so requests routed to the pod during that window are dropped.
Distributed tracing
In a monolith, a slow request produces one stack trace. In a microservices system, a single user-facing request might touch six services before returning. When that request is slow or failing, finding which service is responsible requires stitching together timing data across all six hops.
Distributed tracing works by assigning a unique trace ID to each incoming request and propagating it as a header across every downstream call. Tools like Jaeger and OpenTelemetry collect these traces and visualize the full call chain with per-service timing breakdowns. Without this, you're looking at six separate log files and manually correlating timestamps, which is how debugging takes four hours instead of twenty minutes.
A concrete example: your agent orchestrator calls a context retrieval service, which in turn calls an embedding service, which then calls a vector database. The overall request takes 4.2 seconds. Without tracing, you don't know whether the latency is in the retrieval logic, the embedding model, or the vector DB query. With tracing, you can immediately see that the embedding service takes 3.8 seconds, while everything else is fast.
| Pillar | What does it tell you | Common tools |
|---|---|---|
| Logs | What happened in a specific service | ELK Stack, Loki |
| Metrics | How the system is performing over time | Prometheus, Datadog |
| Traces | Where the request went and how long each hop took | Jaeger, OpenTelemetry |
Security
In a monolith, trust between components is implicit; they run in the same process, so there's no inter-component auth to configure. In microservices, every service-to-service call crosses a network boundary and is a potential attack surface. A compromised service can call any other service it can reach, unless you've explicitly restricted what each service is allowed to do.
The standard approach is zero-trust: no service is trusted by default, regardless of where on the network the call originates. In practice, this means:
- mTLS between services, both sides of every connection present a certificate, so a service can't be impersonated by anything that doesn't have the right cert
- Short-lived JWTs for carrying caller identity across service boundaries, tokens expire quickly, so a leaked token has a limited blast radius.
- Per-service authorization, the fact that a request passed through the API Gateway doesn't mean every downstream service should accept it unconditionally
In an agentic system, this gets more complex. When an AI agent calls a tool execution service, the call must carry the identity of the original user, not just that of the agent. Otherwise, the tool execution service has no way to enforce per-user permissions on what tools can be called. JWT propagation through the full call chain, not just to the first service, is what makes this work correctly.
The API plumbing tax
Every inter-service communication contract requires client code on the consuming end, HTTP clients, request and response DTOs, serialization handling, versioning, and keeping everything in sync as the provider evolves. Across dozens of service pairs, this becomes a significant ongoing engineering cost. Backend engineering team surveys consistently show 30-40% of engineering time going not to business logic but to this integration layer: writing integration code, updating client SDKs, chasing DTO drift, and debugging version mismatches.
For teams using AI coding assistants, this overhead compounds further. REST and gRPC integrations fill the codebase with HTTP clients, DTOs, stub files, and proto definitions, all of which consume AI context window space that could be used for business logic. According to Graftcode's founder, eliminating the integration layer reduces token usage by 30-60% on integration-heavy services, directly improving the accuracy and success rate of AI-generated changes.
Pull requests reflect this, too. With REST or gRPC, an interface change touches the HTTP client, the DTO, the stub, and the business logic across multiple files. With Graftcode, the only thing that changes in a commit is the business logic; the integration layer doesn't appear in the diff because it doesn't exist in the repo.
[7]How Graftcode Eliminates the Integration Tax
Every microservices team eventually hits the same wall. The architecture is sound, the services are well-bounded, the communication patterns are in place, and yet a significant chunk of every sprint still disappears into writing HTTP clients, keeping DTOs in sync, and debugging integration mismatches that have nothing to do with business logic. The architecture solved the scaling problem. It created a new one.
The integration layer between services isn't a one-time setup cost. Every time a service evolves its interface, every consumer needs to update their client. Every new service pair needs a new integration contract written from scratch. In a system with dozens of services, this compounds into 30-40% of backend engineering time spent not on product logic but on glue code, writing HTTP clients, chasing DTO drift, managing SDK versioning, and debugging mismatches that only surface at runtime.
Graftcode is built specifically to eliminate that cost.
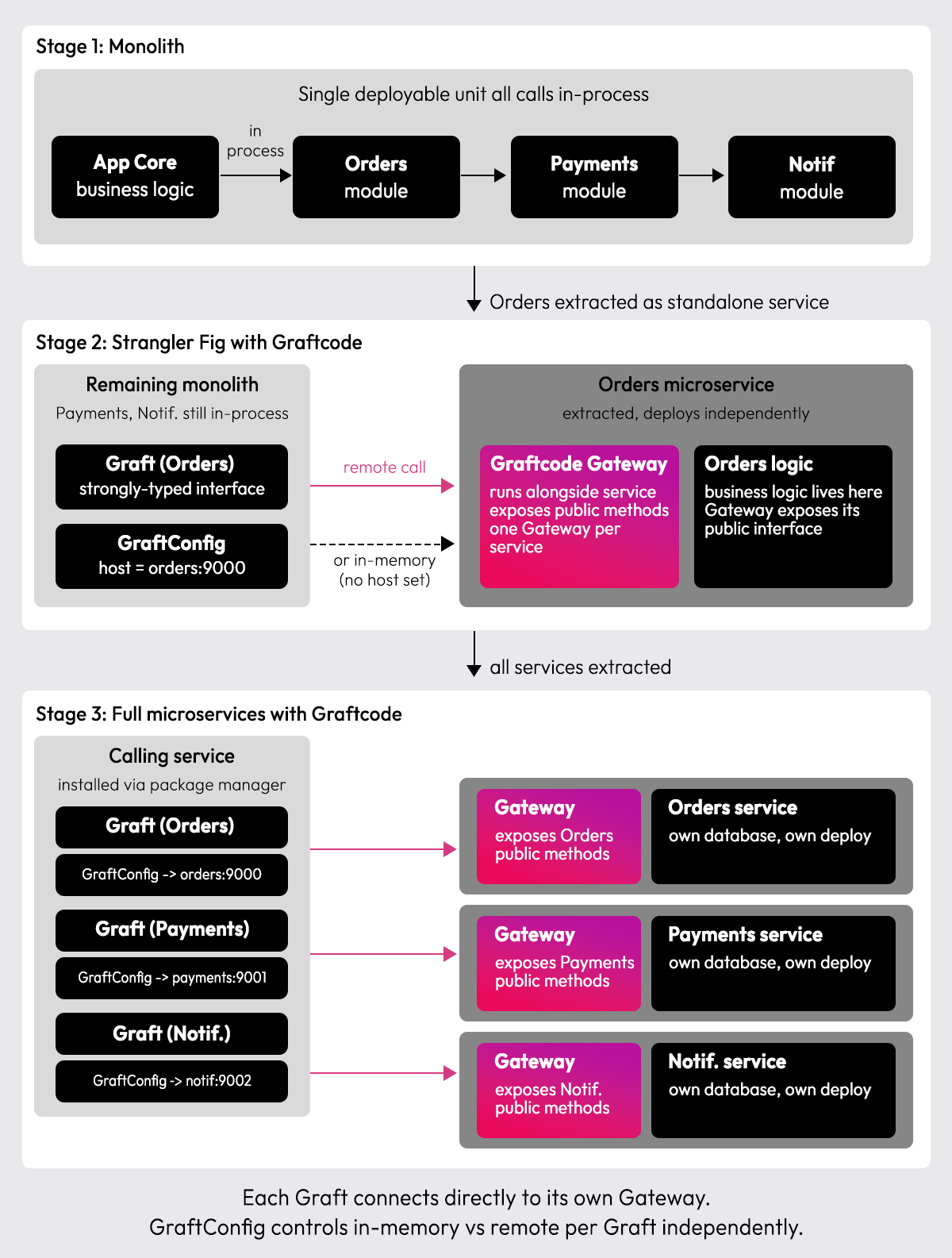
The diagram above shows how a Graftcode-assisted migration unfolds across three stages. In Stage 1, all modules run in-process inside a single monolith. In Stage 2, the Orders service is extracted, and the Graftcode Gateway runs alongside it, exposing its public methods. The remaining monolith installs a Graft (strongly-typed interface) and controls whether the call runs in-memory or remotely via GraftConfig, set via an environment variable or a config file. In Stage 3, every service has its own Gateway, and the calling service has a separate Graft for each service, each configured independently. No central router, each Graft connects directly to its own Gateway.
What Graftcode Actually Does
Graftcode is a cross-runtime communication layer that lets services call each other's public methods directly, no REST endpoints to define, no gRPC proto files to maintain, no message queue contracts to manage. The consuming service runs a package manager command that generates a Graft, a strongly-typed interface, inside the calling service. That Graft is then configured via Graft Configuration to specify whether the call runs in-process or as a remote call to the external service.
On the provider side, the Graftcode Gateway runs alongside the exposing service as a server, responsible for making that service's public methods available to callers. It doesn't sit in the middle, routing traffic between services; it lives next to the provider and exposes its interface. Each extracted service gets its own Gateway. If you have three remote services, you have three Gateways, and three corresponding Grafts in the calling service, each independently configured.
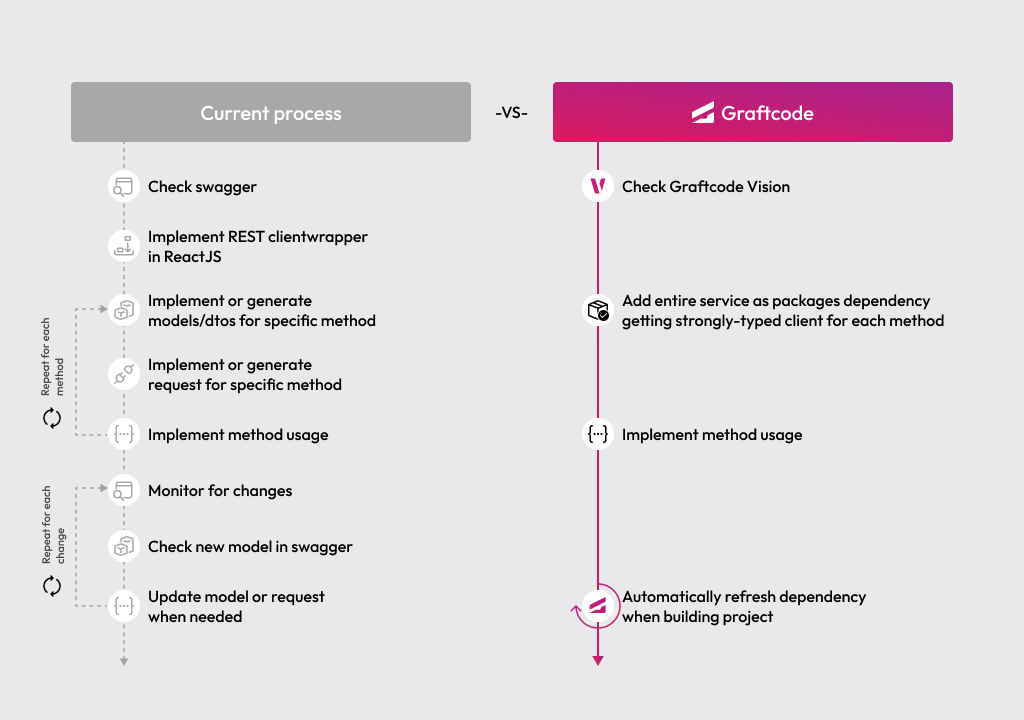
This also changes how AI tools reason about the system during development. A retrieval + execution + summarization loop implemented with REST or gRPC introduces a significant integration surface area: HTTP clients, proto files, stub imports, and DTO mappings that an AI coding assistant has to parse and hold in context. With Graftcode, that surface area disappears from the codebase entirely. The AI context window focuses purely on business logic, improving the accuracy and success rate of AI-generated changes in both greenfield development and the later maintenance and evolution of the system.
From 20 Lines Of Auth And HTTP boilerplate To One Typed Method Call
The generate_comment endpoint has one job: take a Reddit post URL and generate a comment for it. But in a standard setup, before it can do that job, it has to handle everything Reddit-related itself, OAuth token refresh, raw HTTP calls, manual header construction, JSON parsing, and pagination, all of it living in main.py alongside the actual business logic.
# Before -- Reddit auth and fetch logic inline in main.pyimport prawimport requestsdef get_reddit_access_token_from_refresh():response = requests.post("https://www.reddit.com/api/v1/access_token", ...)return response.json()["access_token"]@app.post("/generate_comment")async def generate_comment(request):token = get_reddit_access_token_from_refresh()headers = {"Authorization": f"bearer {token}", ...}response = requests.get(f"https://oauth.reddit.com/comments/{post_id}",headers=headers)# parse raw JSON, handle pagination, error handling...
The problem isn't the auth logic specifically; most teams extract that into a shared wrapper quickly enough. The real cost is everything that comes after: parsing the raw JSON response, handling pagination, managing the response schema as Reddit's API evolves, and doing all of this with no type safety on what comes back. One field gets renamed in Reddit's response payload, and the consuming service throws a KeyError in production with no compile-time warning. Every service that consumes Reddit data owns its own version of that parsing and schema-handling logic, and the type system enforces none of it.
With Graftcode, the Reddit logic is extracted into its own service, reddit_service/reddit_service.py, and the generated typed client is installed in the calling service via pip. The calling service doesn't know or care how Reddit auth works. It just calls a method:
# After -- one typed method call via Graftcodefrom reddit_service.reddit_service import RedditService@app.post("/generate_comment")async def generate_comment(request):post = RedditService.get_submission(url=reddit_url)
The generate_comment endpoint now does exactly one thing. All the Reddit-specific logic, auth, pagination, and parsing live in reddit_service.py and are owned by a single person. If Reddit's API changes, only that service is updated. Every other service that needs Reddit data installs the same typed client and calls the same method, no duplicate boilerplate, no diverging implementations, no scattered knowledge.
How Graftcode Automatically Keeps Service Integration Contracts In Sync
The Grafts Graftcode generates are not static snapshots. They update automatically whenever the provider service's interface changes: a new method is added, an existing parameter is updated, or the return type changes. That change is immediately visible as a package update in the consuming service's package manager, just as any dependency update would appear. The consuming team can update by running the install command or clicking update directly in their IDE. No Slack message asking "hey, did you add a new endpoint?", no digging through changelogs, no waiting for the other team to write documentation.
Interface changes that introduce incompatibilities surface at compile time rather than at runtime in production. A consuming team installs and updates their Graft via a single package manager command, npm install, pip install, maven add, across 20 supported languages and 10 package managers.
This eliminates one of the most consistent sources of microservices production incidents: a provider team ships an interface change, and the consumer team doesn't find out until their deployment fails or a field starts returning null in production.
Switching Between Monolith And Microservice Without Touching Application Code
Because Graftcode abstracts the invocation target from the calling code, switching a service call from in-process to remote is a configuration change, not a code change. A team develops and tests locally with the Graft configured to run in-memory, then sets an environment variable at deployment to route that same call to a remote microservice in staging or production. The calling code doesn't change. The integration contract doesn't change. The Graft Configuration, set either via environment variable or directly in the Graft setup, is the only thing that determines whether the call runs in-process or remotely.
This is the Strangler Fig pattern with the coordination overhead removed. Teams can extract services incrementally, validate them under real traffic, and roll back by changing the environment variable, all without modifying application code.
| Without Graftcode | With Graftcode |
|---|---|
| Write an HTTP client per service pair | Install typed client via package manager |
| Manually define and maintain DTOs | Auto-generated, always in sync |
| Debug version mismatches at runtime | Catch interface changes at compile time |
| No clean path to switch between monolith and microservice, requires permanent architectural commitment and full integration rewrite | Switch between in-memory and remote via environment variable or Graft Configuration |
| Integration overhead compounds with every new service | Overhead stays flat regardless of service count |
Performance At The Communication Layer
Beyond the developer experience, Graftcode's communication layer runs up to 70% faster than web services at runtime. It consumes one-eighth the CPU of equivalent gRPC or REST calls for the same volume of inter-service traffic. For teams running high-throughput internal service communication, inference services, tool execution pipelines, and agent orchestration layers, this is a meaningful reduction in infrastructure cost, not just a convenience improvement.
The integration tax is one of the most consistent and underappreciated drags on microservices teams. Graftcode removes it at the layer where it actually lives, not by changing how you architect your services, but by changing what it costs to connect them.
[8]Conclusion: The Integration Layer Is Where Microservices Succeed or Fail
Getting the architecture right, correct service boundaries, the right communication patterns, and the defensive patterns that contain failures is necessary but not sufficient. The teams that run microservices successfully at scale are the ones that treat the operational and integration layer with the same engineering seriousness as the architecture itself. The ones that don't end up with a distributed monolith that's harder to debug, harder to deploy, and slower to build on than what they started with.
The integration tax is where most of that failure accumulates, quietly, sprint by sprint, until 30-40% of engineering capacity is going to integration code instead of product. Graftcode removes that cost at the layer where it actually lives. To get started, explore Graftcode or go straight to the Graftcode Academy to wire up your first service in minutes.
[9]Frequently Asked Questions
1. What is the difference between microservices and service-oriented architecture (SOA)?
SOA services are coarser-grained, communicate through a central Enterprise Service Bus (ESB), and often share a common data layer. Microservices are fine-grained, communicate directly over lightweight protocols, own their own data stores, and are designed for independent deployability. SOA was built around enterprise integration; microservices are built around team autonomy and deployment speed.
2. How do you handle distributed transactions across microservices without a shared database?
Through the Saga pattern, a sequence of local transactions where each step publishes an event that triggers the next. If a step fails, compensating transactions undo the previous steps. Two implementations exist: choreography-based, in which services autonomously react to events, and orchestration-based, in which a central coordinator drives the sequence. Temporal and Conductor are the most commonly used tools for orchestration-based sagas in production.
3. How does Graftcode eliminate the API plumbing tax in microservices?
Graftcode replaces hand-written HTTP clients, DTOs, and versioning logic with auto-generated, strongly-typed Grafts installed via package manager. When a provider service's interface changes, that change is immediately visible as a package update; teams can choose to update immediately via a single pip install, npm install, or maven add command, or review the change and update on their own schedule. Either way, incompatibilities surface at compile time rather than as silent failures in production.
4. How does Graftcode support monolith-to-microservices migration?
Graftcode abstracts the invocation target from the calling code, so switching a service call from in-process to remote does not require changes to the application code. The switch is controlled through Graft Configuration, set via an environment variable, a config file, or a configuration method called directly on the specific Graft. Teams develop locally with the Graft running in-memory, then configure it to run remotely at deployment. No rewritten integration contracts, no permanent architectural commitment required upfront.
5. When should you use gRPC over REST for internal microservices communication?
gRPC is the better choice when performance, strong typing, and schema enforcement matter. Protocol Buffers produce a binary payload significantly smaller and faster than JSON, and the typed contract catches interface mismatches at compile time. It also supports bidirectional streaming natively, useful for LLM token streaming between services. REST remains preferable for external-facing APIs and browser clients.
6. When should you use Graftcode instead of gRPC or REST for inter-service communication?
Graftcode makes the most sense when your primary pain point is integration and maintenance overhead rather than raw protocol performance. If your team is spending significant time writing and updating HTTP clients, managing DTO schemas, or keeping integration contracts in sync as services evolve, Graftcode removes that entire layer. Unlike gRPC, which requires maintaining .proto files and regenerating stubs manually, or REST, which has no enforced schema by default, Graftcode generates strongly-typed Grafts that reflect the provider's current interface and can be updated on demand via a package manager. It also removes the permanent architectural commitment of choosing between a monolith and microservices up front; the same calling code runs in-memory locally and remotely in production, controlled entirely through Graft Configuration.
7. How does Graftcode improve AI-assisted development workflows?
Graftcode removes the integration layer from the codebase entirely, no HTTP clients, no DTOs, no stub files. For teams using AI coding assistants, this has two measurable effects. First, it reduces token usage by 30-60% on integration-heavy services, according to Graftcode's founder, because the AI context window focuses on business logic rather than protocol boilerplate. Second, pull requests become cleaner; an interface change only touches the business logic files, since the integration layer doesn't exist in the repo. Both effects improve the accuracy and velocity of AI-assisted development, on greenfield systems and during ongoing maintenance
/WRITTEN BY